- Extraction of data from web pages
- Usually not easy to do
- Present the data in orderly fashion
- So it can be used for other purposes
Three problems are answered in this thesis
- Can a data extractor be built, using user examples and XPath?
- Is it possible to increase the quality using context?
- Can automation be built into the system?
- Meant to be viewed by human users
- Contains a lot of structure
- Allows for interaction
What does it take to get a web page to a user?
Server
www.google.com
HTML
→
Browser
Google Chrome
Visual
→
User
Internet detective
The server typically serves HTML content
- Will be processed by the browser
- Looks like a bunch of code? It is a bunch of code
- Can be very pretty
Just like unicorns are
very
pretty horses
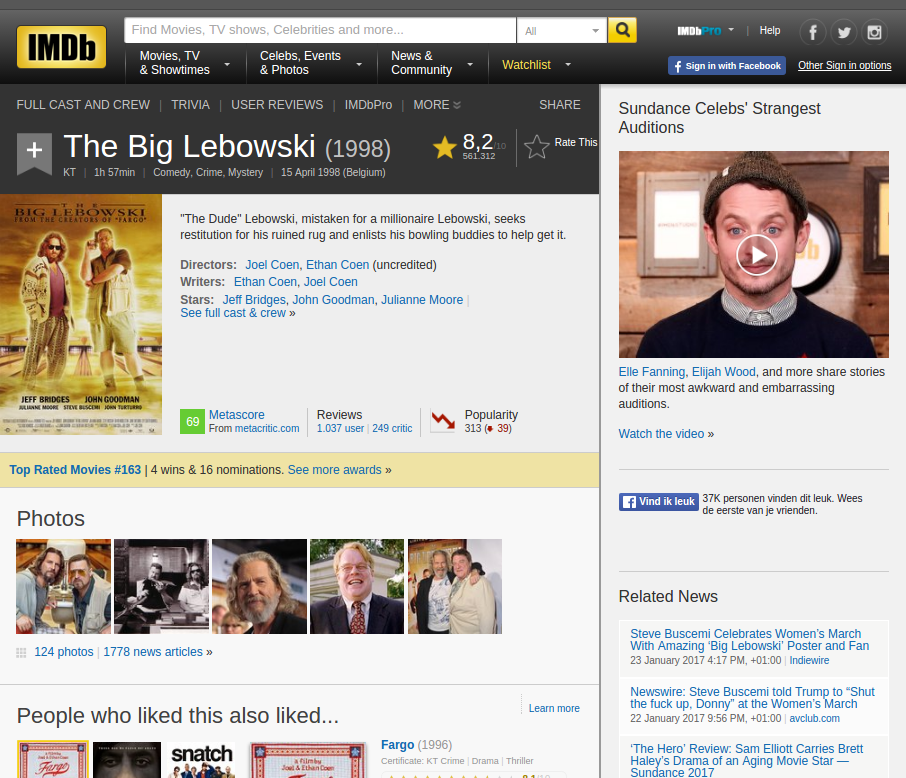
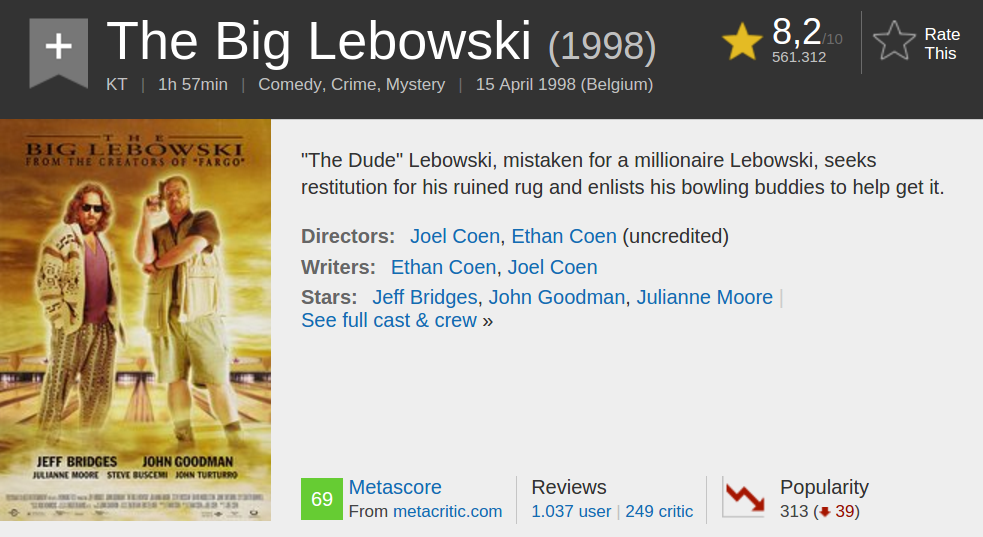
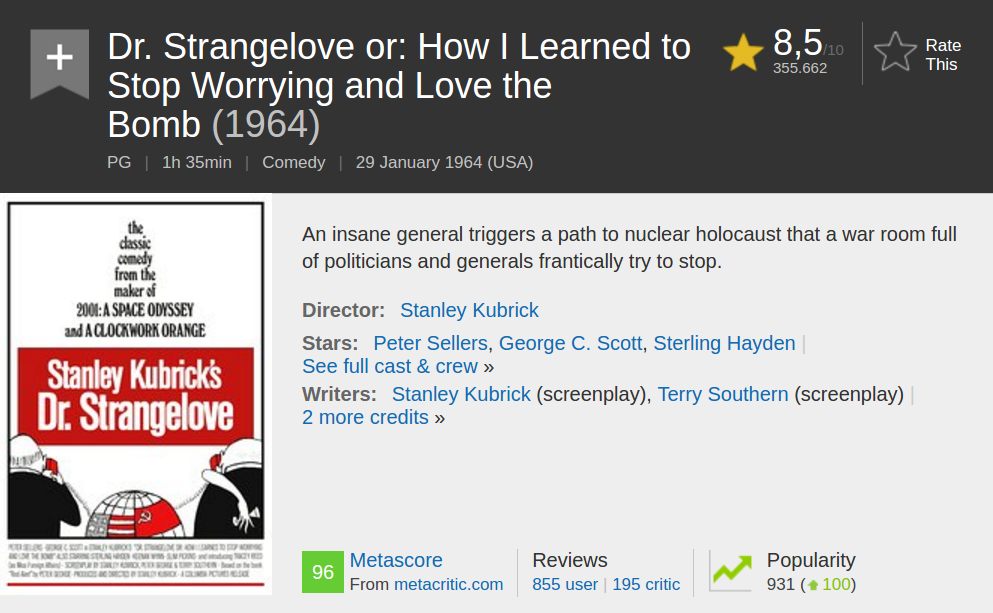
This piece of the IMDB website...
Looks like this as HTML code.
Server
www.google.com
HTML
→
Browser
Google Chrome
Visual
→
User
Internet detective
The browser downloads the HTML and it...
- builds an internal DOM model,
- allows for interaction, modifications, ...
- produces a visual page for the user.
- I love movies
- I want to build my own cinema
- I need to track all the movies i own
- IMDB has the information, but I cannot easily use it
Extract all the stars
Impractical to get all that information manually
- There’s a lot of IMDB content: 4.1 million titles
- What do you do with new movies?
- What about errors corrected by IMDB?
- Let's make it easier!
- Have a program do the heavy lifting
- Ask the user for minimal input: a couple of examples
Assume: each movie page shows
its stars in the same spot
Let's look at the underlying DOM structure
- We need to build a rule: “Get all stars”
- Requires a way to extract elements from DOM
- XPath is a query language
- Can be used to retrieve elements from a structured document
- ... such as the DOM model of a web page
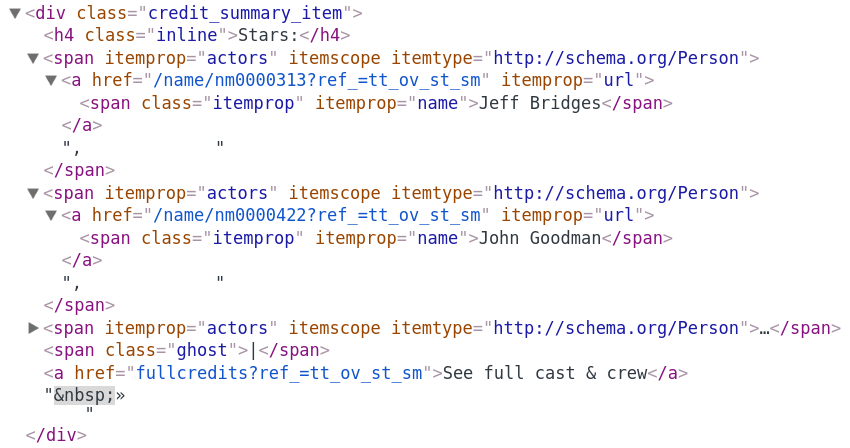
- Makes use of the node names in the DOM (span, a, h4 ...)
An XPath example...
This XPath selects Jeff Bridges from the HTML example:
/span/a/span/text()
XPaths can be very complex, but for now we keep to this structure:
/step1/step2/step3
A step looks like this:
axis::nodetest[predicate]
The full version of the example XPath would be:
/child::span[1]/child::a[1]/child::span[1]/child::text()[1]
- Don’t worry, we’re getting there.
- Remember the examples we have to give to the system?
We can now point to the user's examples with XPaths!
Considering n XPaths, create a single one that does the same: a generalised XPath
- Remove anything that is not similar!
- /div[1]/span[1]/a[1]/span[1]/text()[1]
- /div[1]/span[2]/a[1]/span[1]/text()[1]
- This leaves us with an XPath that selects all actors
- /div[1]/span/a[1]/span[1]/text()[1]
It's not that simple.
- The structure of documents is not always that similar
- We need a nice way of making generalisation always possible
Finding and exploiting similarities has been done with strings
- A string is a list of characters, e.g., "thedude"
- Edit distance between two strings a and b
- = the minimal amount of edit operations to transform a into b
- Add character
- Remove character
- Replace character
For example, "Thedude" can be transformed in "Teddy" by:
- Removing the h
- Removing the u
- Replacing e by y
Leading to an edit distance of 3
Using the edit distance, an alignment can be calculated!
Thedude
T ed dy
This is also possible for multiple strings
We can use this alignment for our XPaths!
Instead of characters in strings...
...we use the XPath /s/t/e/p/s in the XPaths.
Now it's for real, these are some user XPaths!
- /html[1]/body[1]/div[2]/div[1]/table[1]/tr[1]/td[1]
- /html[1]/body[1]/div[2]/div[2]/table[1]/tr[3]/td[1]
- /html[1]/div[2]/div[2]/table[1]/tr[3]/td[1]
A possible alignment:
- /html[1]/body[1]/div[2]/div[1]/table[1]/tr[1]/td[1]
- /html[1]/body[1]/div[2]/div[2]/table[1]/tr[3]/td[1]
- /html[1]/. /div[2]/div[2]/table[1]/tr[3]/td[1]
The result: /html[1]//div[2]/div/table[1]/tr/td[1]
- A single generalised XPath
- That retrieves all the original examples
- Possibly even more?
The generalised XPath solves the first problem:
Given some user examples, find all the relevant items.
Solution:
- Convert all user examples to XPaths
- Align and merge the examples, create generalised XPath
- Execute the generalised XPath on web pages
Generalised XPaths work well for:
- Documents with a lot of structure
- Uniquely identifiable structures
- Not much replication
Problematic situations exist where structure alone is not enough
For example!
Imagine two web pages with a similar structure
But, disaster...
someone made a mistake.
Probably Frank
3rd row 2nd rowBased on these examples...

The generalised XPath
will be too general.
- Exploit more than just structure
- Look around for helpful evidence or context
- Exploit text
- Exploit styling
- Exploit common ancestors
XPath predicates already helped us:
- html[1]/body[1]/div[2]
- div[child::a] → select a div that has an a child
- div[preceding-sibling::table]
- div[preceding-sibling::text()=”Stars”]
Add predicates to generalised XPath
to make it more
narrow
.png)
- Not allowing undesired results ...
- ... increases data extraction precision
- In this work, 6 types of predicates are proposed
- They are automatically added
- A preparation step is needed
- Build set of indicated nodes
- Build set of overflow nodes
<body>
<div>
<span>
<b>Some bold statement</b>
</span>
</div>
</body>

Using the examples, build this generalised XPath
/body[1]/div//span[1]/b[1]...which results in one undesired node
The nodes that we travelled through on the way to an example are indicated nodes, others are overflow nodes
/body[1]/div//span[1]/b[1]- The generalised XPath targets too much
- Use predicates to narrow the scope
- Find out a suitable predicate
- Automatically
- Based on rules and context
- Not too restrictive
- Should still be readable
- The desired b tags all have a span parent and div grandparent
- This can be added as a predicate to the span tags
- The indicated nodes fulfill it
- ... and the overflow nodes don't
- Result: /body[1]/div//span[1][parent::div]/b[1]
In this work, 6 predicates are proposed
- Each fulfills a specific purpose
- Easily expandable
Tests indicate increased precision
- Less undesired elements are retrieved
- Positive impact on overall quality
Can everything up until now be somehow automated?
Consider this question in the context of
set expansion
- Begin with a set of elements
- Automatically expand that set with relevant elements
Let's say we already know a set of movie titles





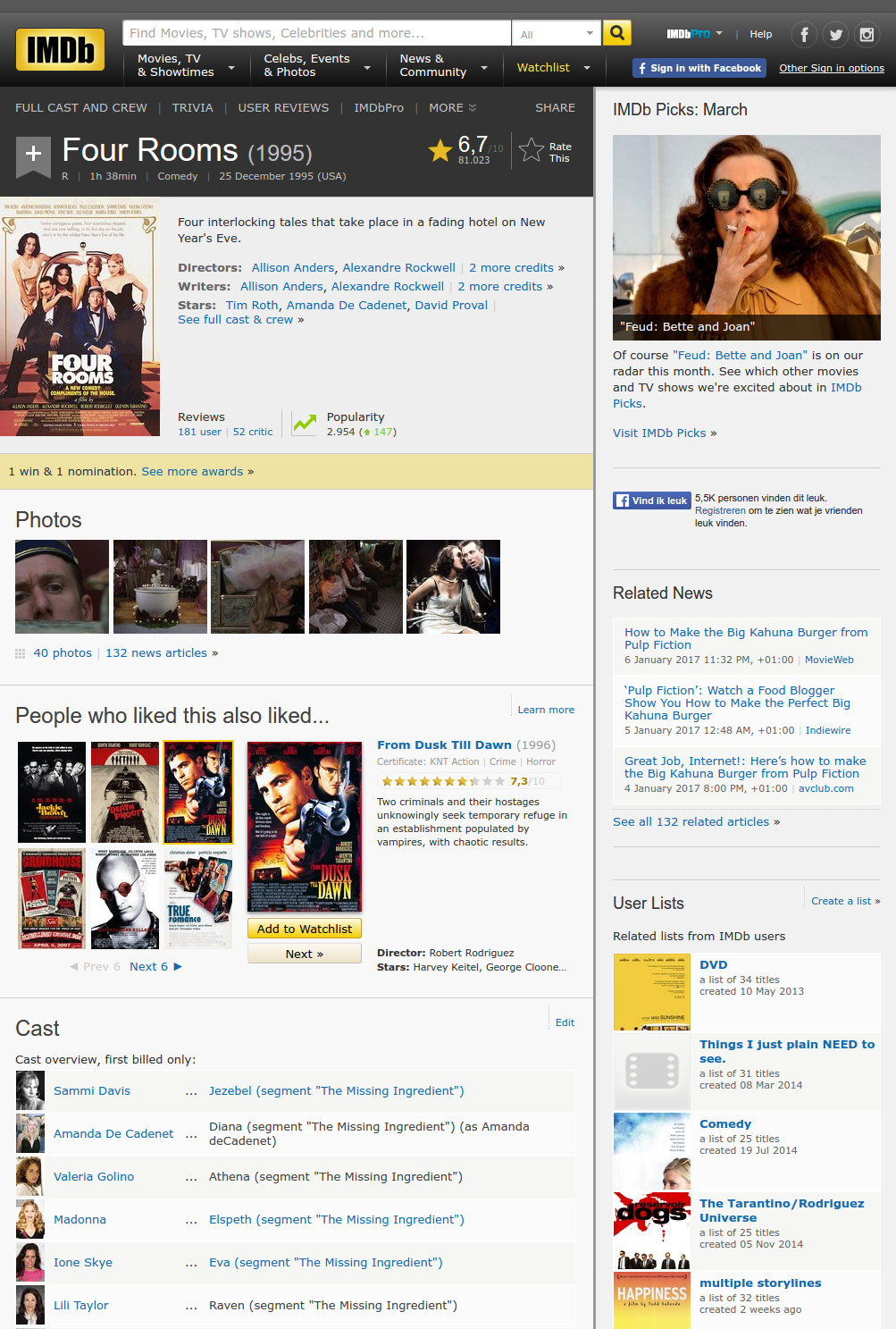
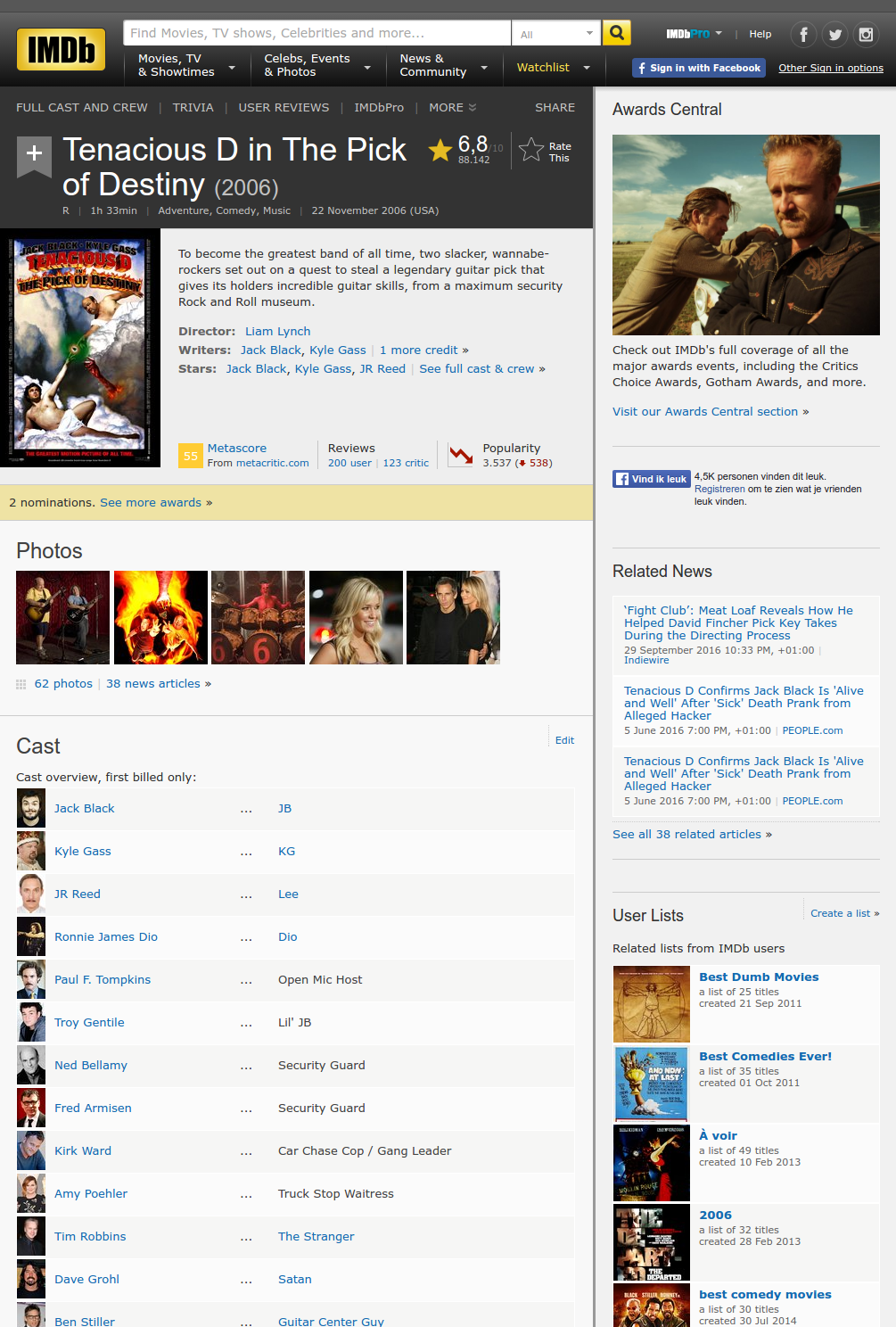
- Look for the titles we know
- Figure out rules for them
- Generalise XPaths of the found titles
- For each match, generate its XPath
- If there are multiple on a page
- Cluster the XPaths
- Similar XPaths get grouped together
- Each cluster results in generalised XPath
Assume that known movie titles are found multiple times on the known web pages
- /body[1]/html[1]/div[2]/div[4]/h1[1]
- /body[1]/html[1]/head[1]/title[1]
- /body[1]/html[1]/div[2]/div[4]/h1[1]
- /body[1]/html[1]/div[2]/div[4]/div[1]/div[1]/a[1]/b[1]
- /body[1]/html[1]/div[2]/div[3]/h1[1]
- /body[1]/html[1]/div[1]/div[3]/div[1]/div[1]/a[1]/b[1]
- Has similar XPaths
- They can be generalised!
A cluster is merged...
- /body[1]/html[1]/div[2]/div[4]/h1[1]
- /body[1]/html[1]/div[2]/div[4]/h1[1]
- /body[1]/html[1]/div[2]/div[3]/h1[1]
...into a generalised XPath
- /body[1]/html[1]/div[2]/div/h1[1]
Repeat execution of generalised XPath on:
- The known web pages
- Could contain lists of movie titles?
- Maybe multiple pages contain a single title on the same place?
- Web page on which nothing was found yet
- Maybe we can find new items?
- This expands the original set!
Main focus: Data extraction from (semi-)structured documents.
The following problems were investigated:
Thank you for your attention
Any question is well appreciated!